
サブスタ番付を攻略せよ!
Substack番付サイトのデータからアルゴリズムを推測してみた話

この記事では「Substack番付」のアルゴリズムをウミノが勝手に分析(想像)した結果を書きます。
やみくもに記事を書くよりは攻略のヒントになるはずなので、ぜひどこに行っちゃったかわからなくなる前に、リスタック(シェア)しておいてくださいね。
「Substack番付」ご存知ですか?
Substack番付は、だいき | サブスタ番付 さんが運営されているサイト。Substack上で注目されている日本語記事のランキングをまとめてくれています。
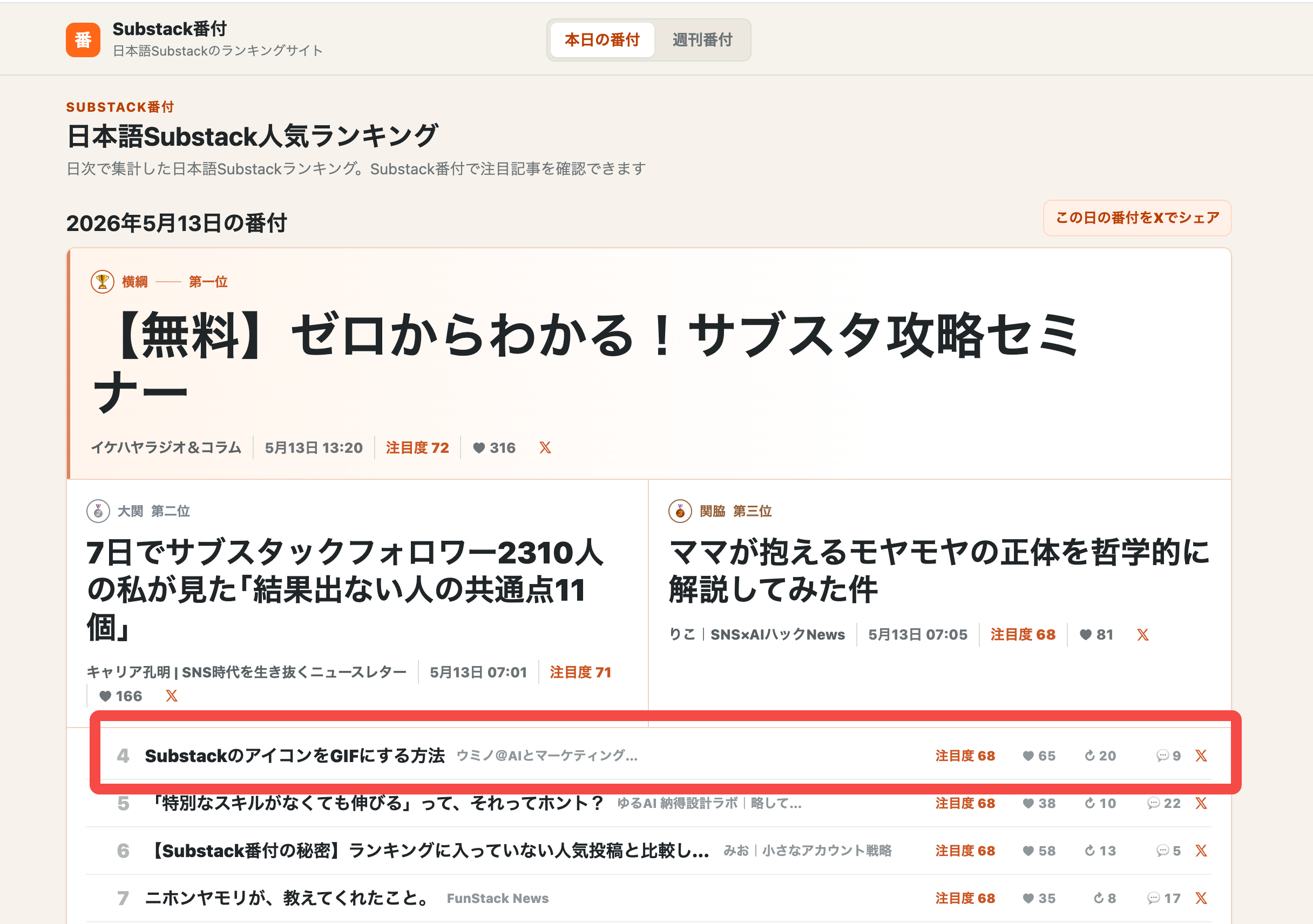
実はわたしもこういう日本のSubstackのランキングサイトをCodexで作ろうとしてたんですが、「Substackの教科書」の執筆が忙しくて途中で諦めちゃったんですよね。

\現在期間限定で無料エリアを大幅拡大中です/
だいきさんはいち早く動かれていて素晴らしいです!!

わたしもありがたいことによくランキングに掲載いただいているのですが、自分の記事が載るたびに「うれしい」と思うと同時に
これってどういうアルゴリズムでランキングされてるんだろう?
と、ずっと気になってました。
というわけで、この記事では想像も含みますが、こんな感じかなぁ〜というのを好き勝手に分析してみます!
わたしが勝手に想像してるので実際の計算式は違うはずですし、今後変わる可能性もあります。あくまでエンタメとしてお楽しみください。
公式情報を読んでみよう
Substack番付には「ランキングのしくみ」という独立したページがあります。ここの内容をまずはチェックしましょう。
Substack番付とは
Substack番付は、記事を日次・週次で集計してランキングにしたものだそうです。
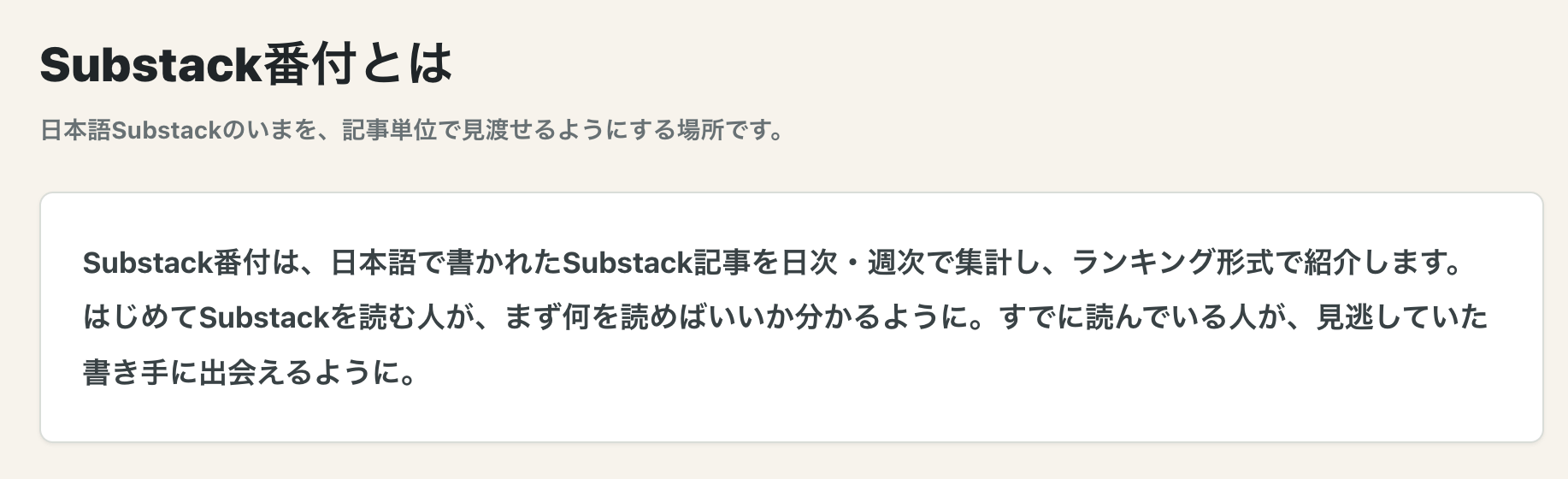
記事単位でランキング
ユーザーアカウントや出版物単位ではなく、「記事」の単位でのランキングです。
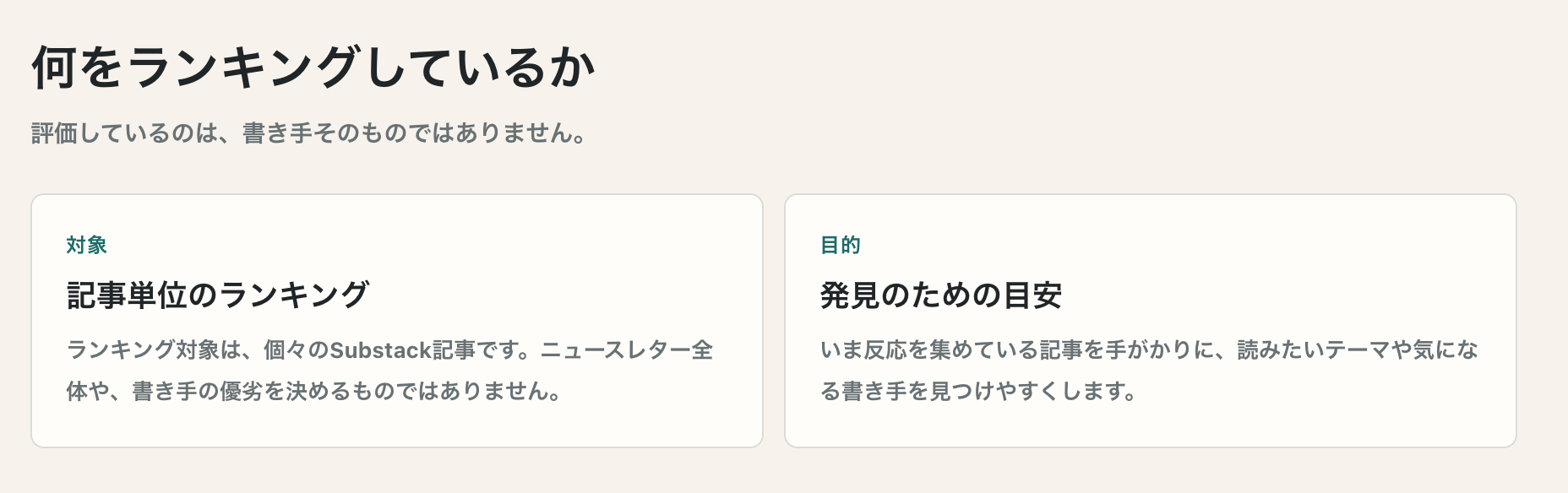
集計方法
ここが知りたいところ。以下の4つをもとにスコアを計算しているそうです。4つめの注目度をどう計算しているかがキモですね。
いいね
Restack数
コメント数
独自スコアである「注目度」
更新のタイミング
ここも重要です。 かなり大きなヒントが書かれていますね。
日次番付は0:00〜23:59に投稿された記事を翌日集計
週間番付は月曜〜日曜に投稿された記事を集計
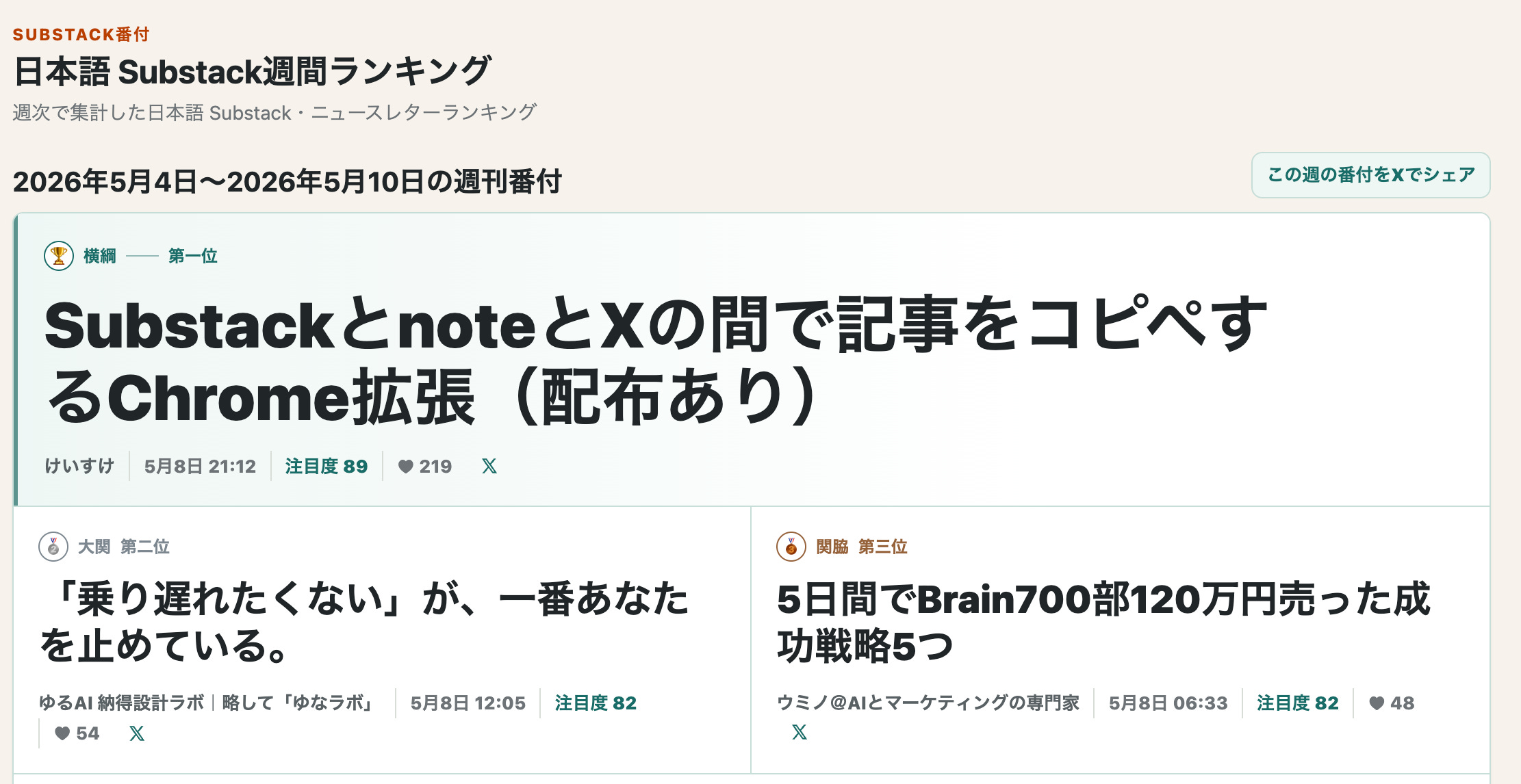
たとえばこの記事を書いてるのは5月14日(木)ですが、5月4日(月)〜10日(日)の週間番付が表示されています(わたしの記事も3位!)
ここからわかることは、極端にいうと23:59に投稿すると日次番付には載りっこないということです。つまり、朝〜昼に出そう!
独自スコア「注目度」の計算方法を考える
番付は注目度順に並んでいるので、これがわかればハックできます。
しか〜し、公式の「ランキングのしくみ」ページを読んでも、
複数の反応を組み合わせた独自スコアです。単純な人気投票ではなく、記事を見つけるための指標です。
としか書いてない。まぁそうですよね。
でも運用する側としては、ここがいちばん気になるわけです笑
ということで、各記事の注目度・♥・Restack・コメント数から関係性を計算してみました。
結論から言うと、完全には特定できなかったけど、運用上どこに力を入れるべきかは見えたので、検証メモとして残しておきます。
⚠️ 繰り返しますが、このアルゴリズム自体はサイト運営者のだいきさんが独自に設計されたもので正確な計算式は公開されていません。「だいたいこういう挙動になっているんじゃないかな〜」というネタとして読んでください。
STEP 1:サイトに出ている数字を並べる
番付ページに行くと、各記事ごとに注目度・♥・↻Restack・💬コメントの4つの数字が並んでいます。
注目度という独自スコアはサイト側で計算済みの結果が表示されるだけで、計算式そのものは見えません。
ただ、入力(♥・↻Restack・💬コメント)と出力(注目度)が両方サイト上に出ているので、ここから計算できるかも?というスタートラインです。
STEP 2:単純な反応合計とスコアの関係を見る
まず単純に「♥ + 💬 + ↻」を足し算した合計と注目度を比べると、5/13日次でこうなります👇

注目すべきは 15位。反応合計が175あるのに、注目度は64。 逆に10位は反応合計25しかないのに68。 当然といえば当然ですが、ただの足し算ではなさそうです。
STEP 3:重みをつけて足し算してみる
そこで「♥1個、コメント1個、Restack1個」をそれぞれ違う重みで式にしてみます。 具体的には、
重み付き合計 = ♥ + α・コメント + β・Restackの α と β を、過去7日分のサブスタ番付に出ている合計210件の数字を使って、 総当たり(α と β の組合せを0.5刻みで細かく振って、もっとも実際の注目度に近づく値を探す)で計算すると、
日次:α ≈ 2.5(コメント)、β ≈ 3.0(Restack)くらいに着地しました。 つまりかんたんに表すと
♥ 1個 = 1点
コメント 1個 = ♥ 2.5個分
Restack 1個 = ♥ 3個分
の重み付けです。
「Restackの方がコメントよりちょっと重い」「♥はいちばん軽い」のが、データから出てきた結論です。
「Restackの方がエンゲージメント高そう」とは思ってたんですが、コメントもRestackもほぼ同じくらい効くというのが意外でした。ちなみにこれは日次番付の話です。
ただ、この重み付き合計をそのまま注目度に対応させようとしても、まだ合わないんですね〜。
たとえば5/13で、
1位の記事:重み付き合計 ≈ 406
10位の記事:重み付き合計 ≈ 45
重み付き合計で見ると 9倍 も差があるのに、注目度は 72 vs 68 で4点差 しかないんですね。むむむ。
STEP 4:重み付き合計を「ケタ(log10)」で潰す
そこで、重み付き合計を log10(ケタ数)に変換してみたら、ようやくきれいに注目度に近づいてきました。
log10 は 10倍ごとに1ずつ増えるスケール。たとえば、
重み付き合計 10 → log10 = 1
重み付き合計 100 → log10 = 2
重み付き合計 1000 → log10 = 3
つまり「10の倍数の方が、線形よりも数字が圧縮される」というやつです。 これに係数(傾き)をかけて、ベース点に足す形でフィッティングすると、
日次の注目度 ≈ 39.5 + 13.7 · log10( ♥ + 2.5·コメント + 3.0·Restack + 1 ) − 4.4 ·(ペナルティフラグ)
↑ 重み付き合計のlog10くらいに落ち着きました。 (ペナルティフラグの話は後述します)
log10 を使うとどう効くかというと、こういう関係になります👇

つまり、重み付き合計を10倍にすると注目度が約+13点上がります。2倍にしただけだと+4点しか上がらない。
反応が多くなるほど、追加点の伸びが鈍るのがlog系の特徴です。
これで「♥316の1位(重み付き合計406)」と「♥13の10位(重み付き合計45)」が同じくらいの注目度(72と68)に入ったりする現象も、log10で潰せばケタ数の差が小さくなるので説明がつきます。
そしてもうひとつ、log系の地味に大事なポイントが、初動の方が、1個の重みが大きいということ👇

すでにバズってる記事とほぼ無風の記事に同じ数のコメント・Restackが加わったとしたら、無風の記事のほうが注目度の伸びが大きいんです。
STEP 5:計算式の精度確認
提示した式が実際にどれくらい当たるのか、5/13番付の30件で予測値と実値を比較しました👇
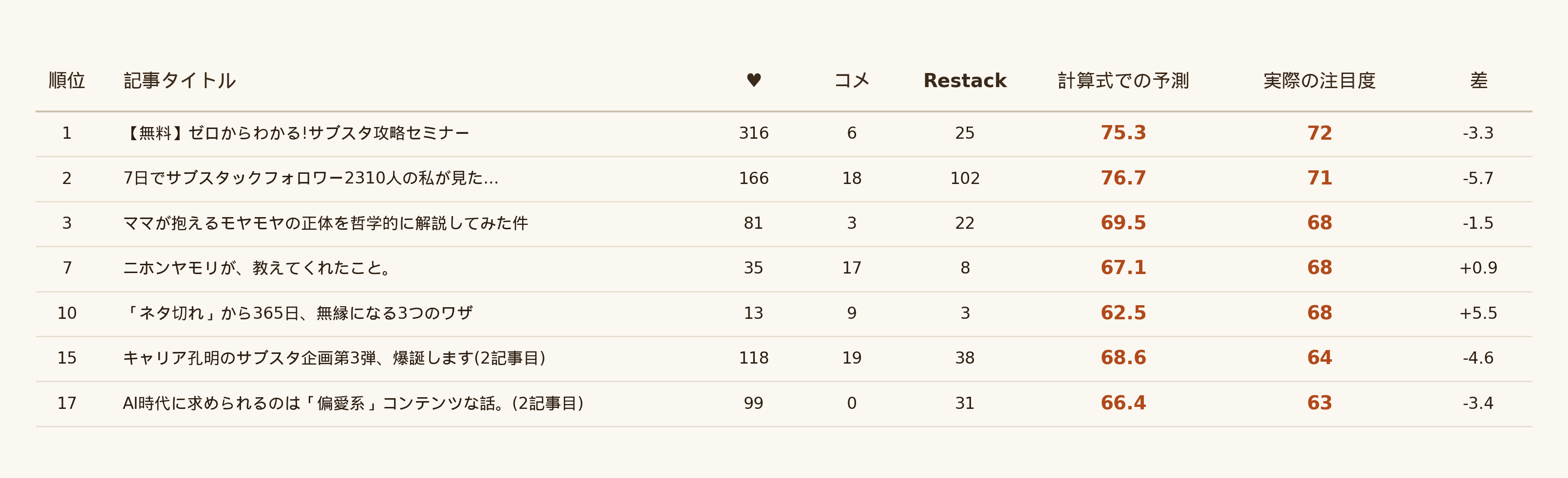

平均絶対誤差は約2点、予測誤差が±5点以内に収まる記事が9割。
表示が整数で四捨五入されている影響もあるので、これくらいの当てはまり方であれば、ざっくりの傾向は捕まえられている近似式 と言って良さそうです。
ただし、同点が並ぶ部分(5/13は3〜10位がすべて68点)の中での順序や、±5点を超えてズレる記事もあるので、ピンポイントの値ではなく「だいたいこのくらいのスコアになる」程度の見方が安全です。
ペナルティの正体:同じ書き手が複数記事を出すと、上位以外は減点される
検証中に気づいたんですが、同じPublicationが同じ日(または同じ週)に複数記事をランクインさせると、「一番反応を集めた1記事だけは通常通り、それ以外は約−4点減点」されているっぽいです。
たとえば5/13の番付では、同じPublicationから2記事入っていた書き手がおふたりいらっしゃいました👇
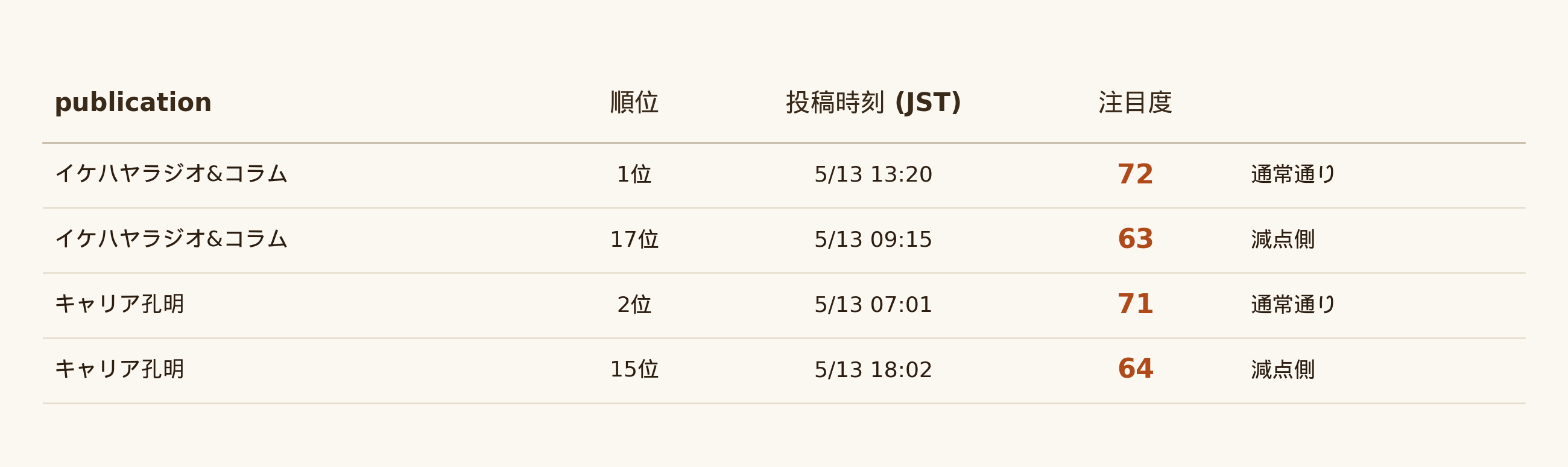
ただ、投稿の前後関係はバラバラなんです。
イケハヤさん:先に投稿された記事(09:15)が減点側、後で投稿された記事が通常通り
キャリア孔明さん:後で投稿された記事(18:02)が減点側、先に投稿された記事が通常通り
つまり、「先に出したから/後に出したから」ではなく、「そのPublicationのなかで反応を集めた方の記事だけが通常通り、それ以外の記事の注目度を減点する」という調整っぽいです。
両方とも計算式で予測した注目度より、減点側の記事は 3〜5点ほど低く 出ています。7日分の記事をみても、このペナルティの係数が安定して−4.4点くらいで出てきたので、偶然じゃなさそうです。
おそらく、Substack番付サイトのコンセプトが「人気の上下を競う場所ではなく、読みたい記事に出会う入口」と書かれている通り、ひとりの書き手が上位を独占しないように、ベスト1記事以外は抑えるという設計になっているんじゃないかなと思われます。
番付に載りやすくする3つのコツ
ここまでの計算式を踏まえて、わたしが「実際に効きそうだな」と思った運用上のコツを3つに絞ってお伝えします。
コツ①:♥より「コメント」「Restack」を呼ぶ設計を意識する
STEP 3で出した重み付けがこれ👇
日次:コメント1個 = ♥ 2.5個分、Restack1個 = ♥ 3個分
週次:コメント1個 = ♥ 7〜8個分、Restack1個 = ♥ 3〜4個分特に週次番付ではコメントが圧倒的に効くようです。♥を10個もらうより、コメントを2個取れる方が重み付き合計が大きくなる、ということです。
読者がひとこと書きたくなる構成——問いかけで終わる、自分の体験を重ねたくなる話題、賛否がある主張——を選ぶと、自然と重み付き合計が伸びてきます。
コツ②:朝〜昼に投稿する
公式の説明にも書いてありましたが、日次番付は「0:00〜23:59に投稿された記事」が対象で、翌朝に確定します。
つまり、23:59に投稿したら、反応を集める時間はほぼゼロ。
単純に考えても「反応を集める時間が物理的に短いから、反応数が少なくなる → 重み付き合計が増えにくい → スコアも自然に下がる」となりますよね。
なので、日次番付の上位を狙うなら、朝〜昼の投稿が無難です。また、週次番付に乗せたいなら、週の前半(月〜水)に渾身の記事を投稿するのが理想的です。(週の後半で伸びるからね)
コツ③:同じ日に2記事出さない
同じPublicationが同じ日に複数記事をランクインさせると、上位以外は約−4点減点されるので、複数記事出しても損するだけです。
日次番付を狙うなら1日に1記事に絞って、エネルギーを集中させた方がトータルのスコアは伸びやすいです。
計算しながら気づいたこと
計算ロジックそのものは見えないので、データから当てに行く
肝心の計算ロジックは当然非公開なので、サイト上に出ている注目度・♥・💬・↻ の数字を全件並べて、関数フィットで推測しました。100%は無理だけど、80%くらいは見えました。
週次データだと、当てはまりが急に悪くなる
日次でうまく当てはまった計算式(20.8 + 25.2 · log10(♥ + 7.8·コメ + 3.4·Restack + 1))を週次に当ててみると、こんなズレが出ます。
たとえば 2026/5/4〜5/10 の週次番付。
1位:SubstackとnoteとXの間で記事をコピペするChrome拡張(配布あり) by Keisuke / けいすけ さん ♥219 + 💬14 + ↻108 計算式での予測注目度:約92点 → 実際:89点(差 −3、ほぼ予測通り)
13位:キャリ孔ファミリーへ。本気で世界変えに行く。ついてこい。 by キャリア孔明 さん ♥217 + 💬67 + ↻111 計算式での予測注目度:約98点 → 実際:76点(差 −22、大きく外れてしまう)
わたしの計算式どおりなら、13位のキャリア孔明さんの記事は 本来1位の記事より高い注目度(約98) が出てもおかしくない数字。
なのに、実際の注目度は76で、予測から22点も下に外れています。
しかも、両方とも投稿日は 5/8(木) でほぼ同条件なので、投稿時期で説明することもできません。
ここで計算式が大きく外れる理由は、外側からは完全には特定できませんでした。考えられる仮説としては、
その書き手の普段の反応量に対する「伸び率」で評価している
Publicationの規模で正規化されている(フォロワー数で割っている、など)
同一発信者ペナルティが、過去複数週にまたがって効いている
あたり。週次は単純な反応量だけでは説明できない、別の補正が混ざっている、というのが現時点での結論です。
同点が多すぎて、順位が一意に決まらない
5/13は3〜10位が全部「注目度68」。8件が同点です。
おそらく内部的には小数までスコアを持っていて、表示するときに四捨五入で整数にしているので、外から見ると同点に見えるのかなと。
同点内の並び順は、たぶん♥数の降順とかで決めているはずですが、ここまでは外側からは分かりませんでした。
まとめ:Substack番付に載りたいならここを意識しよう
♥より「コメント」「Restack」を呼ぶ設計を意識する
朝〜昼に投稿する
同じ日に2記事出さない
公式に「人気の上下を競う場所ではなく、読みたい記事に出会うための入口」と書かれている通り、書き手向けのKPIではなく、読者向けの発見ツールとして設計されている、というスタンスがスコアの作り方からも見えました。
なので、番付の順位を追いかけすぎるよりは、「読者が記事を発見しやすい状態」を整えるほうが、結果的にスコアも付いてくる、という設計思想なのかもしれません。
ちょっと長くなりましたが、「番付の中身ってどうなってるの?」という同じ気持ちを持ってた人の参考になればうれしいです👏
最後に、 だいき | サブスタ番付 さん、運営ありがとうございます!
というわけでこの記事にもコメントを残してリスタックしてね〜
「Substackの教科書」がおかげさまで1000部売れました〜🙌
豪華特典(教材読み込ませたGPTsとnote記事からコピペできる拡張機能)ついてます!
▶︎ https://brain-market.com/u/taracomom/a/b3MzN2QjMgoTZsNWa0JXY

レビュー特典もあるよ。

\現在期間限定で無料エリアを大幅拡大中です/
参考:
ランキングのしくみ:https://substackbanzuke.com/about
ウミノさんすごすぎます!ここまで分析されるとは...!おかげでとっても学びになりました!ありがとうございます。
緻密な検証。とても面白い内容です!